ResBuilder | Building a Trustworthy AI Resume Builder for Real People
 By Karim
By Karim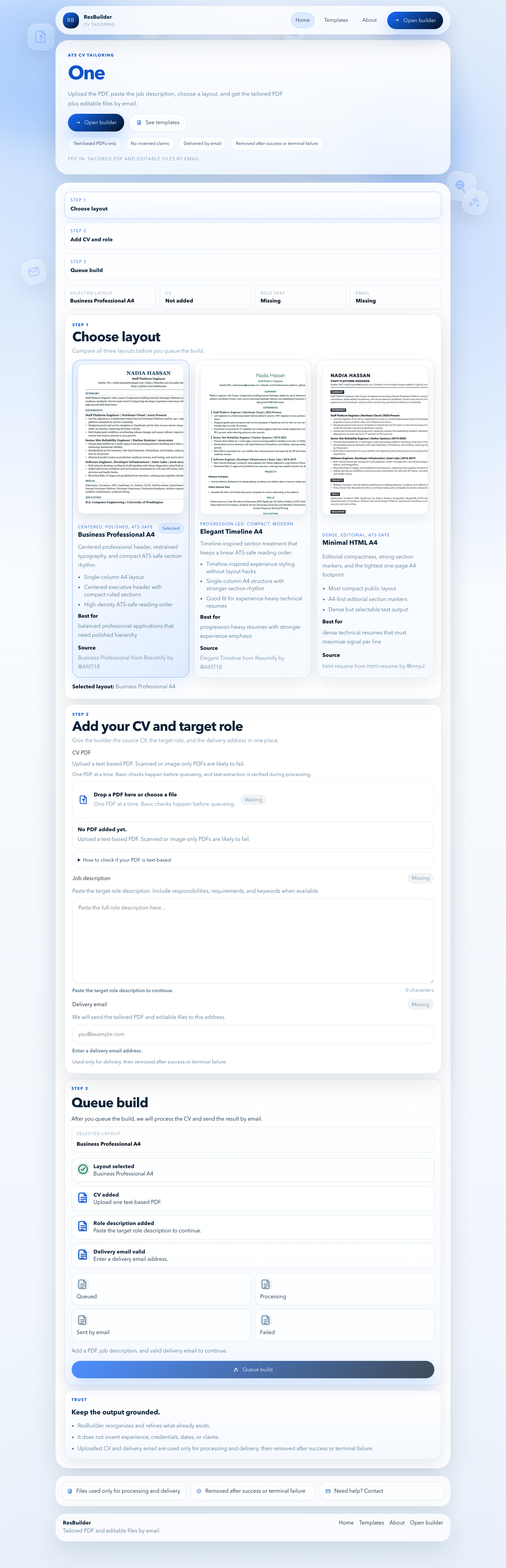
Building a Trustworthy AI Resume Builder for Real People
One evening a friend sent me five job posts and one message: I cannot keep rewriting my resume for every role and still stay honest. That message became the starting point for this project.
The context was simple. People already have real experience, real timelines, and real pressure. They need a way to adapt language for each role while keeping every claim true and readable by hiring teams and screening systems.
ResBuilder was designed for that exact moment. It takes the source resume seriously, aligns it with a target role, and produces a tailored output that keeps trust intact.
Live product
- Main builder: https://resbuilder-theta.vercel.app/
- Templates: https://resbuilder-theta.vercel.app/templates
- About: https://resbuilder-theta.vercel.app/about
The architecture idea: separate thinking from writing
Early versions taught an obvious lesson: one big model call is fragile.
So I moved to a staged architecture with clearly defined responsibilities:
- Meta-prompting stage: generate role-specific reviewer instructions from the incoming job description and market context.
- Review stage: extract evidence from the source CV and classify job terms into supportable vs unsupported.
- Builder stage: write the final tailored resume only under strict evidence and compactness constraints.
I designed this as a multi agent system so failures stay explainable and fixable.
When something goes wrong, I want to know:
- was the issue prompt intent,
- evidence extraction,
- builder behavior,
- or render-time constraints?
That separation made iteration dramatically faster.
Task definition: make the model solve the right problem
A lot of AI systems fail because they define the task too loosely.
I made task definition explicit:
- Input truth source: original CV is ground truth.
- Allowed transform: reframe and reorder while preserving factual claims.
- Forbidden output: unsupported tools, fake timeline changes, fabricated credentials.
- Target constraint: exactly one-page A4 final output.
By giving the system strict boundaries, we reduced ambiguity and made quality measurable.
Tool usage strategy: grounded generation with verification
The pipeline combines tool assisted context, structured checks, and model reasoning:
- role-context retrieval for job market grounding,
- structured validation of model outputs,
- PDF rendering,
- automated delivery and status tracking.
The key principle: models generate candidates, tools verify reality.
Prompt engineering techniques that actually moved quality
The biggest gains came from a few disciplined techniques:
- Meta prompting where an upstream instruction writer creates a role tuned reviewer prompt from the job description and market context before evaluation begins.
- Structured outputs with fixed keys and strict schema validation.
- Contrastive in-context examples:
- examples where supported keywords must be inserted,
- examples where unsupported terms must remain excluded.
- Repair prompting with pinpoint errors that specify exactly what to correct.
- Evidence-led instructions: every keyword addition must map to source evidence.
- Compactness contracts for one-page output (summary size, bullet budgets, section priority).
The result was a shift from “creative generation” to “constrained rewriting.”
Communication channel design: reliability through clear state
User trust depends on visibility, so communication was treated as a product surface:
- explicit stage statuses (
extracting,reviewing,building,compiling,emailing), - delivery notifications,
- failure notifications with restartability,
This eliminated the “silent black box” feeling and made the system operationally transparent.
CI/CD thinking: quality gates before confidence theater
I wanted deploy confidence to come from measurable evidence.
So release flow is gated by:
- static checks,
- multi-layer tests,
- end-to-end journey validation,
- benchmark-style predeploy validation on canonical fictional data.
The important point is failure containment.
Each historical failure mode is converted into an explicit guardrail.
Testing philosophy: prioritize behavior level confidence
Testing is split by intent:
- Unit tests for validation logic, schema contracts, and failure handling.
- Integration tests for pipeline state transitions and artifact flow.
- End-to-end tests for user journey confidence.
- Benchmark checks for template preservation, one-page enforcement, and keyword support quality.
This gives broad confidence across both model behavior and infrastructure behavior.
What I wanted this system to represent
I built this for people who need help applying faster without compromising honesty.
The goal was to make AI dependable in real hiring workflows.
That required:
- architecture that isolates responsibilities,
- prompts that constrain behavior,
- tools that verify outputs,
- channels that communicate status clearly,
- and operations that recover gracefully under failure.
If there’s one takeaway, it’s this:
Trustworthy AI products are engineered systems first, and model wrappers second.